A descriptive text transcript (including all relevant visual and auditory clues and indicators) is provided for non-live, web-based audio (audio podcasts, MP3 files, etc.). A text or audio description is provided for non-live, web-based video-only (e.g., video that has no audio track).
A descriptive text transcript OR audio description audio track is provided for non-live, web-based video
¿Cómo pueden beneficiar las transcripciones a la docencia en la UCR?
METICS recibe apoyo para la creación de MOOCs (Massive Open Online Courses)
Proyecto a cargo de la Vicerrectoría de docencia de la UCR
"UCR lanza nueva plataforma para cursos virtuales a cargo de METICS" (UCR, 2015)
"METICS abrirá más de 500 cupos para formar docentes en el 2015" (UCR, 2015)
No todo el material creado por los docentes es accesible, visible y acorde con la legislación sobre accesibilidad
De nada sirve tener el mejor material del mundo si no se puede consumir!
Evaluación de algunos videos
Video original rescatado de Youtube
Observaciones: subtítulos no corresponden a monólogo, no se usó un diccionario especializado en el algoritmo de reconocimiento de voz, sin embargo fue útil usar YouTube para obtener un script con segmentos de voz (fuente: Arturocamachoclases YouTube, 10/11/15).
¿Cómo obtener transcripciones de video?
Usar servicios web de transcripción automática (YouTube, Vimeo)
Usar software de reconocimiento de voz, e.g. Neto Dragon Natural Speaking
Para tener buenos resultados hay que entrenar software previamente
Solo funcionan con el hablante del entrenamiento
Contratar a terceros (~$1 por minuto)
Hacerlo uno mismo usando software especializado (e.g. MAGpie, dotSUB)
Ejemplo WebVTT (.vtt)
2
00:00:07.038 --> 00:00:08.617
pero si le conviene
3
00:00:08.959 --> 00:00:12.011
es esta fórmula que exista acá
Otros formatos incluyen: Time Text Markup Language (.TTML) ~ XML o SubRip text (.srt)
¿Es posible prescindir de herramientas ajenas?
1. Para crear transcripciones:
El tener el script con inicios/finales de voz ya es la mitad del trabajo en el proceso de transcripción
No hace falta subir videos a hosting externo para obtener esos archivos
Se puede usar un algoritmo de reconocimiento de voz (VAD) localmente:
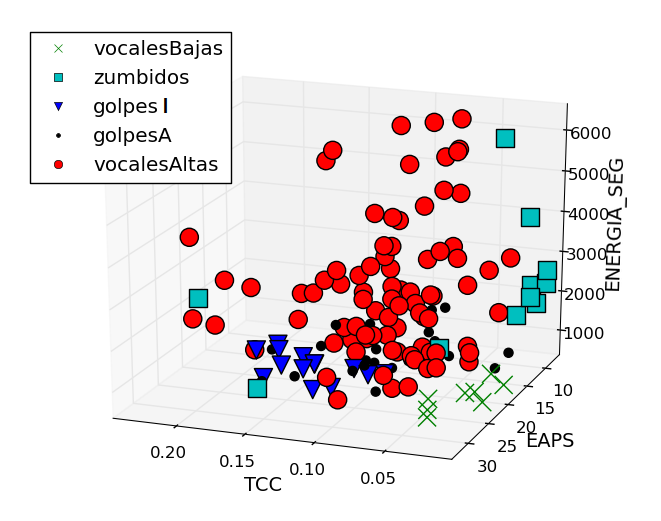
e.g. Detección de voces y otros ruidos en ambientes de trabajo y estudio. Fonseca-Solís, J. M. (juanmaVAD)
2. Para hacer pruebas de calidad:
Transcripciones son verificadas manualmente y de forma aleatoria
No tiene sentido si se puede lograr de forma automática y exhaustiva
Hay que ofrecer prueba para reconocer voz "in vivo" (vs. "in vitro")
Esperar voz en los momentos donde hay transcripciones, sino fallar caso de prueba
Ofrecer prueba de UI complementaria a Selenium en Visual Studio
Objetivos a desarrollar
Objetivo general: evaluar la calidad del VAD propuesto en el JOCICI2015 como herramienta para la creación y verificación de transcripciones
Hipótesis nula: algoritmo no es apto como herramienta de transcripción a menos que la precisión y exactitud para reconocer voz sea mayor del 80%
Estrategia: recopilar colección de videos de TedX y evaluar que tan bien predice los momentos de voz el juanmaVAD
Ventajas: transcripciones ya están hechas, no hay problemas de licencia
Objetivos específicos:
Recopilar colección de videos y sus metadatos
Implementar una versión completa del algoritmo juanmaVAD en algún lenguaje
Actual: Python, deseable: javascript
Incorporar autómata para descartar golpes aislados
Redactar caso de prueba para evaluar juanmaVAD con colección de videos
Procesar videos de antemano y guardar segmentos detectados
Comparar segmentos detectados con transcripciones originales y calcular las métricas deseadas
Investigar formas de ofrecer juanmaVAD como librería de pruebas, en caso de resultar exitoso
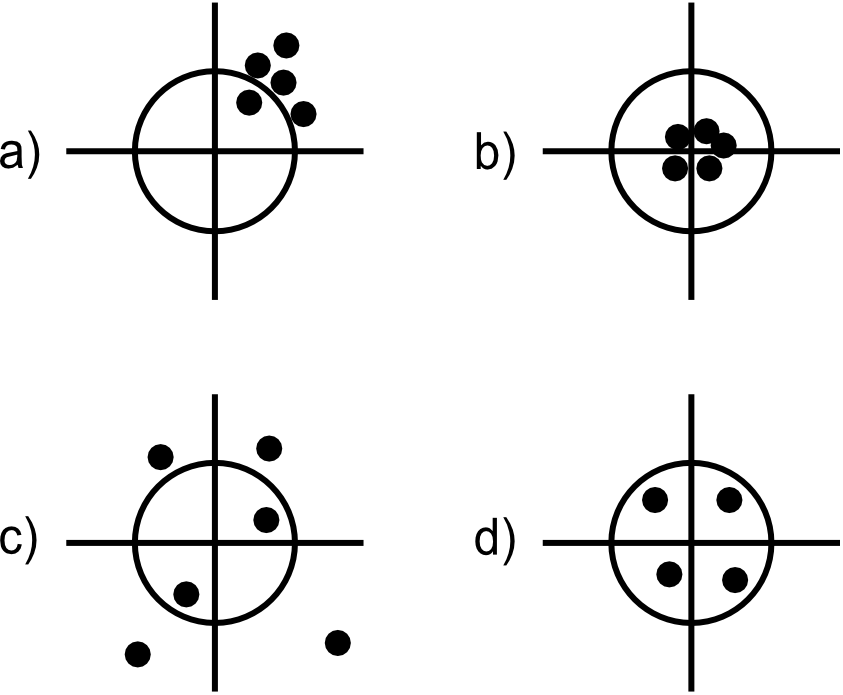
Métricas a calcular
Exactitud: de todas las predicciones positivas y negativas hechas, cuántas fueron correctas [Wikipedia 2015]
Precisión: de todos las predicciones positivas hechas, cuántas fueron ciertas [Wikipedia 2015]